Rating:
### Square Ctf 2018 --> MATH category: Captcha
### Concept
* Solve math, Identify Characters, Work with Fonts Style!
### Given
* A web page to solve mathematical expression and answer to get the flag (sounds easy!)
### Think, Think, Think
* But, when the expression or characters are copied, they appear as garbage, page source show different mapping --> This is because of the custom font style use
d which is base64 encoded within the page
* Oldschool, tried solving the challenge by manually typing as fast as I can, but it was clever to change in a few seconds to a different mapping and captch, th
e page is linked with a token that keeps track of the current captcha... (To probably work and solve it in under 4 seconds else it reset everything!!!!)
* Obtaining the web page with captcha programmatically --> make sure you set the user agent for http proper, else the page doesnt respond
* Tried studying font styles and cmap tables
```
**- IDEA1:** a proper mapping from font style to the characters visible would help to reconstruct the expression (Font tools in python was helpful, but studying the different fonts was not exhaustive, it involved how they are drawn and different tables that define fonts)
**- IDEA2:** use character recognition using OCR, and construct the expression to solve
**- IDEA3:** Try extract the base64 encoded font style into a ttf file and try processing in the current operating system to recognize, (the reverse) to rebuild the expression fron the webpage becomes tough again
```
* Expression could be solved easily as a string with python eval
* Moving forward with the IDEA2 after a number of fails
* Take screenshot of the browser loading the expression - (by python selenium lib)
* Testing OCR capabilities in online ocr tools worked 100% accurate, translating the expression
- Approach1: Take screenshot of the browser loading the expression --> send to a online OCR website (API) --> Fetch the expression text --> Solve
* Some website work for sure (manual upload), while the ones that offer API key access do not work successful
- Approach2: Use python OCR - PYTESSERACT to perform OCR and obtain the text (This seems to not be accurate, some characters are not properly recognized ao it cant be relied upon)
* Refactoring this logic helped me solve the problem, look at the steps
- Fails: Using pillow to increase resolution, contrast, tryc cropping and enhance image did not help. Still OCR was inaccurate!
- Success: Using a hybrid method (@steps), making OCR a separate process to map the characters to text
### Steps
**1. OBTAIN DATA (SCREENSHOT + HTML)** - Use Python Selenium to do this
* Goto the captcha webpage
* Take screenshot of the captcha page and save as png
* Also, store the page source html
**2. OCR (Create a mapping for fonts)**
* We already know performing OCR on the screenshot is not accurate using pytesseract
* We know that the expression could contain only '1234567890-+xX\()'
- xX for multiply, should be replaced by '*' once the expression is obtained
* Replace the content of the html source (ie the expression) with the string 'unique characters in expression that would map to 1234567890-+xX\()' with proper spaces for the OCR to work (REASON: The spacing and the way the characters are displayed affect the OCR process a lot!!!!!!)
- This process can also be improved by making fewer character mapping (as we have only less characters to map) repeatedly to be more accurate (this was not needed for this challenge though)
* Now again repeat the process step 1 and OBTAIN DATA with the new html created, this time take a new screenshot with the known characters and order you have placed.
* The OCR now seems to be more accurate and the mapping between the font and characters could be performed easily.
**3. CONSTRUCT EXPRESSION**
* Construct the expression now, replace 'x' with '*' and execute it with eval
**4. SUBMIT CAPTCHA RESPONSE**
* Obtain the token and the answer, create a JSON and make a POST request to submit the answer
-- It is noted that I have added one round trip of selenium action for the new html with added characters to get the mapping with better OCR. Hope this doesnt cost be enough time!!
### Program:
- crack_structured.py
- crack.py - initially worked on code with different pocs
```python
import os, re, sys
import requests
import pytesseract
from selenium import webdriver
### STEP1 - Obtain Data
# Use selenium to grab a screen shot of the webpage
driver = webdriver.Firefox()
driver.get('https://hidden-island-93990.squarectf.com/ea6c95c6d0ff24545cad')
element = driver.find_elements_by_tag_name('p')
# Html source, token and expression
htmls = driver.page_source
text = element[0].text
t = "".join(list(text))
tok = driver.find_element_by_name("token")
token = tok.get_attribute("value")
var = list(set(t))
vars = []
for ch in var:
if ch.strip():
vars.append(ch)
print vars
print htmls
### STEP2 - OCR - Recogize and Map
html = htmls.replace(text, " ".join(vars))
#print html
new_html = open("new.html","w")
new_html.write(str(html))
new_html.close()
alt_html = "file://"+os.path.abspath("new.html")
driver.get(alt_html)
screenshot = driver.save_screenshot('expression.png')
driver.quit()
expression = pytesseract.image_to_string(Image.open("expression.png"))
expression = expression.split()[1]
expression = list(expression)
print vars, expression
### STEP3 - Construct expression
for k,v in zip(vars, expression):
text = text.replace(k, v)
print text
# Replace x or X and solve
#expr = expression.split("\n")[1]
expr = text.replace("x","*")
expr = expr.replace("X","*")
print expr
ans = eval(expr)
print ans
### STEP4 - Submit the answer
url = "https://hidden-island-93990.squarectf.com/ea6c95c6d0ff24545cad"
data = dict(token=token, answer=str(ans))
r = requests.post(url, data=data, allow_redirects=True)
print r.content
```
### Terminal Output showing the work
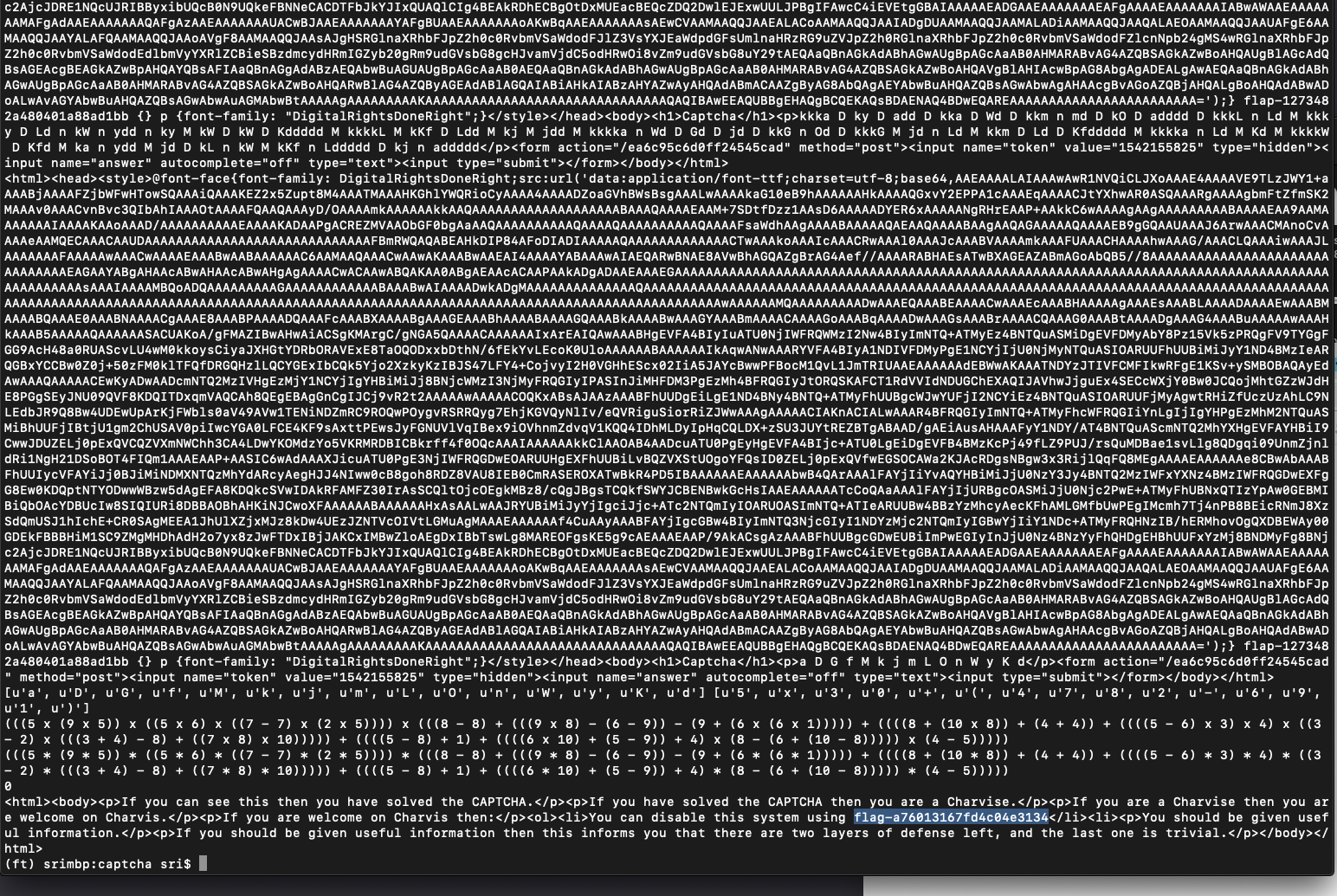
### Flag Obtained

### RESULT
* The first try failed, second try failed too with incorrect answer response
* The third try was successfull!!!!



