Tags: reverse-engineering ghidra x86-64 python3
Rating: 5.0
# Fword CTF 2020
## Auto
### Disclaimer
This is a write-up of how I, glamorous_noob of the team kawaii-hexabutts did this challenge. I am new to CTFs, so I don't have any guarantee about quality. It is possible that better and faster solutions or write-ups exist. That being said, I hope you find something useful in here.
Also, since this write-up aims at being as clear as possible, I will organize the walkthrough in a "more ideal" way compared to what happened in reality. Namely, I won't talk about the things I wasted time on, and will I appear more skillful than I really am. It's up to you to know that this is not true, and that I'm just an aspiring glamorous noob.
Have fun reading! (and, you know, happy hacking)
### First impression
This challenge is called "Auto". When downloading the archive from the CTF platform you read something along the lines of "You might need a robot for this", and when you extract said archive, you find 400 files named `outxxx` where the `xxx` part is a number between `000` and `399` both included.
The challenge is SCREAMING automation, and that's a very useful piece of information to keep in mind as you'll see in the next sections. Knowing I'd have to automate something, my main focus was on similarities and differences between files.
### Getting the big picture
I started by importing the first two files, `out000` and `out001`, in my go-to tool for static analysis, Ghidra. Searching for strings seemed like a sensible first step, and here's what I found in `out000`:
Same strings were found in the other file.
Following the `"GOOOOOOOOOOOOOOOOOOOD"` string reference, we find that it's used in the main function. Although I usually prefer assembly if I'm looking to correctly understand the code (with some exceptions), I like the decompiler view in Ghidra and how it gives a general idea of the function's flow of execution. Here's how the main function looks like in `out000`, before any intervention from my part (focus on the parts I underlined/ framed):
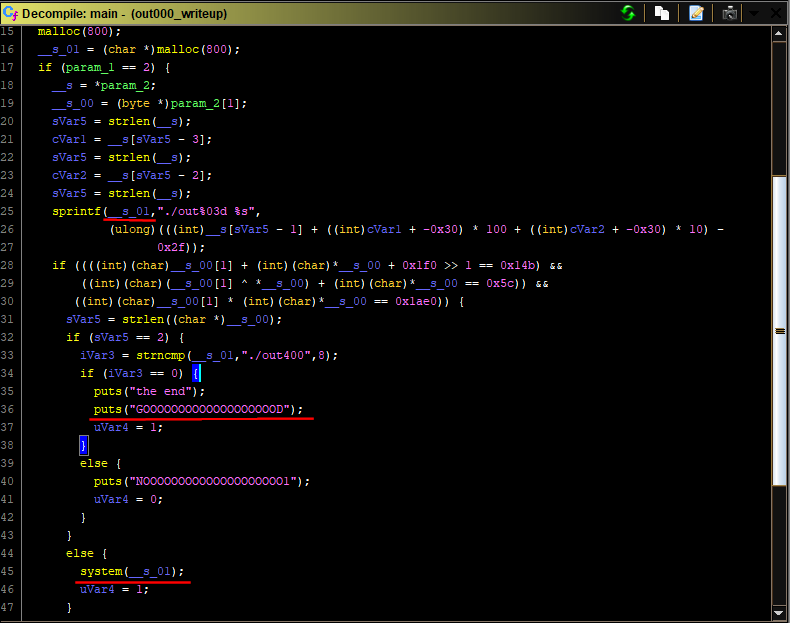
Without diving in details, we can see some interesting stuff:
- `param_2[1]` in the `main` function is definitely a command line argument. `param_1` is definitely `argc`. This program takes one command line argument. That will be our input and that's what will control the program's behavior.
- Two outcomes in these if/else scenarios are interesting, the one where `"the end"` get printed, and the one where the `system` function gets executed.
- If the `system` function gets executed, it will do so with the string used as a destination for the `sprintf`call on line 25
Without getting lost in the details, let's look at `out001` and see how similar it is to `out000`!
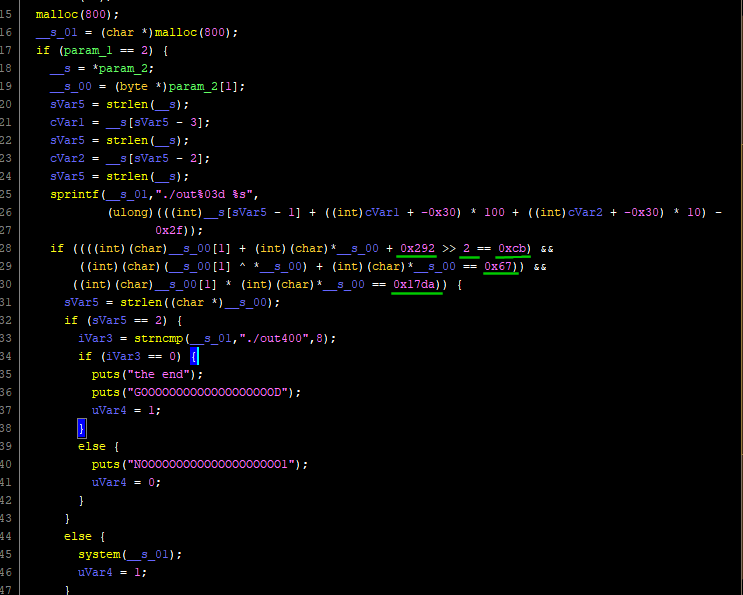
It's almost identical to `out000`'s main function, except for the 5 values I underlined. I suppose then that all 400 hundred files have exactly the same code, except for the 5 values that change every time, and that I would need to:
1. automatically extract these values from all files
2. do something with them
And that's pretty sufficient for a "big picture" view of this challenge.
### Extracting the values
A little pause from the analysis to see how one would go about extracting these values from the 400 files. My go-to language in these situations, like many other people, is python. My approach for the extraction was this:
1. Hardcode the offset for each needed value
2. Open every file, read it, get the values at the hardcoded offsets
First things first, I needed to make sure that the values existed at the same offsets across all files. Looking at these screenshots from `out000` and `out001` respectively, we can see that the first constant (`0x1f0` in `out000` and `0x292` in `out001`) has consistently the same virtual address `0x1012f3 + 3 = 0x1012f6` and is coded on 4 bytes in little endian.


The only thing missing is to know the real offset in the binary corresponding to this virtual address (the version of Ghidra I'm using doesn't keep that kind of information). For this I can think of two ways:
1. The less reliable way, is to make the educated guess that if the virtual address here in Ghidra is `0x1012f6`, the the offset is the least significant two bytes, `0x12f6`, without the added `0x100000`.
2. The more reliable way, is using objdump (it has to be a 64bit version of objdump) with the `-F` option. So it gives something like `objdump -dF out000 | less` and then you'll see the offsets.
Applying the previous logic to all 5 constants gives me all 5 offsets needed to make this piece of code
```python
def read_constants(filename):
f = open(filename, 'rb')
data = f.read(0x1380) # highest offset needed is 0x1371, so reading only 0x1380 is enough
f.close()
offset = 0x12f6
a = unpack('<L', data[offset:offset+4])[0] #interpreting the 4 bytes as a little endian integer
offset = 0x131d
b = unpack('<L', data[offset:offset+4])[0] # same
offset = 0x134b
c = unpack('<L', data[offset:offset+4])[0] # same
offset = 0x1371
d = unpack('<L', data[offset:offset+4])[0] # same
shift = data[0x131b] # the value is coded on only one byte in the executable
return a,b,c,d,shift
```
The superior reader might notice that `shift` exists at a smaller offset than `b`, `c` and `d` and yet it comes after them in my code. That's because I realized it varied from one file to another only half-way through after I'd already coded this function. Sue me.
### What to do with these values
Now that we can have our values whenever we want, comes the greater question: what to do with them?
Well, first of all, we know that they are used in some mad if statement leading to where we want to go. If the condition in that if statement evaluates to false, we will go to the `NOOOOOOOOOOOOOOOOOOOO` part. So now all we have to do is to understand the math in the if statement, and understand how our input to the program will affect it.
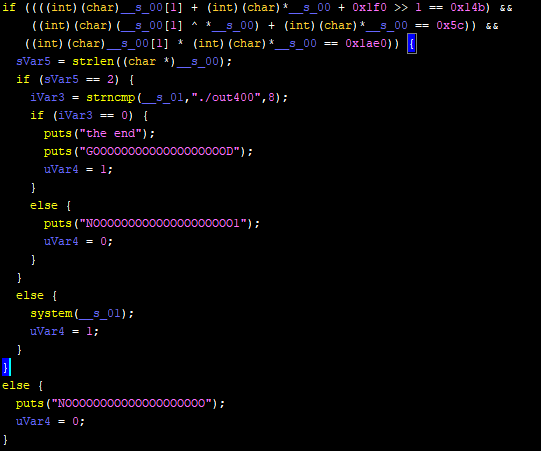
You *could* just try to figure it out from the decompiler's version, and maybe fight your way through retyping and renaming, but I think this is one of the cases where I prefer by far the assembly approach. Let's take it step by step:
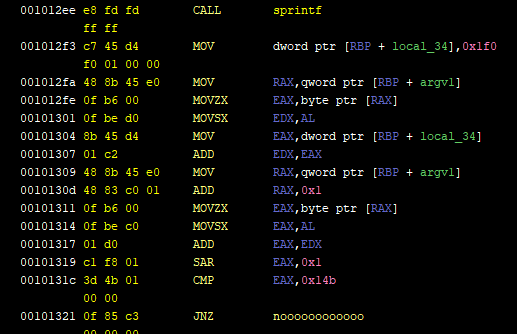
Here's the assembly part showing what happens right after the `sprintf` call that we saw in the decompiler window. I went ahead and renamed some labels and stack variables like `argv1`. It can easily be done by checking the references of when the variable was used (especially when it was written to) and deducing what it contains. `local_34` is a default name. Same thing for the `noooooooooooo` label, I just followed it and saw it lead to printing the "No" string.
Anyway, here's some pseudo-code of what this assembly does:
```
put the byte argv1[0] in EDX (instructions from 0x1012fa to 0x101301)
Add 0x1f0 to it (instructions 0x1012f3 & 0x101304 & 0x101307)
put the byte argv1[1] in EAX (instructions from 0x101309 to 0x101314)
Compute their sum
Shift the sum 0x1 to the right
If the result is not 0x14b go to hell
```
Without forgetting that `0x1f0`, `0x1`, and `0x14b` change from one executable to another, let's write this in python.
```python
user_input="Something YADA YADA"
X = user_input[0]
Y = user_input[1]
a = 0x1f0
b = 0x1fb
shift = 1
if ((a+X+Y)>>shift)!=b:
return False #yeah yeah illegal use of return statement but you get the gist
```
Okeey first formula that our input should validate has been found! Without forgetting, of course, that `a`, `b`, and `shift`vary across files, and that each file will have the same formula but different values for constants. How to actually craft input to satisfy the conditions will come later in this write-up.
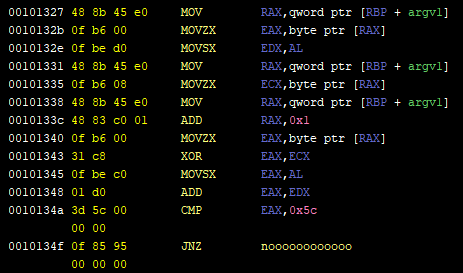
Now for the second formula, I won't detail what instructions do as I did for the first one, but here's the pythonic translation:
```python
X = user_input[0]
Y = user_input[1]
c = 0x5c
if (X + (X ^ Y)) != c:
return False #yeah yeah illegal use of return statement but you get the gist
```
And last but not least here's the third part of the if statement. Notice that if we survive the `JNZ` instruction, we will reach the the `strlen` statement that the decompiler shows *inside* the if block. We will get out of the if statement and finally get closer to our goal.
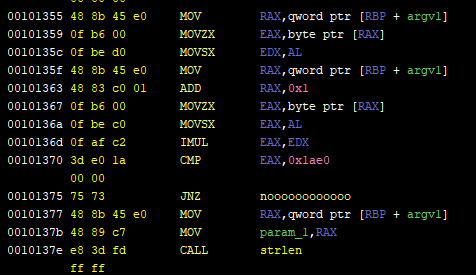
```python
X = user_input[0]
Y = user_input[1]
d = 0x1ae0
if X * Y != d:
return False #yeah yeah illegal use of return statement but you get the gist
```
### Solving for `X` and `Y`
To cut to the chase I'm going to show you my final python function for finding `X` and `Y`, and I will comment on the most important "gotchas" after.
```python
def find_bytes(a,b,c,d,shift):
alphabet = printable[:-6] # all printable characters that are not white space
min_sum = (b<<shift)-a # direct interpretation of the 1st formula ((a+X+Y)>>shift) == b
max_sum_excluded = min_sum + 2**shift # Because information is lost after right shift. More on that later
for s in range(min_sum, max_sum_excluded): # s represents X+Y
for character in alphabet: # iterating over all possible values for X
X = ord(character)
Y = s - X
if X + ( X ^ Y) == c: # do current values for X and Y validate the 2nd formula?
print('Found candidates', X, '&', Y, 'for s =', s)
if X * Y == d: # do current values for X and Y validate the 3rd formula?
print('--> Confirmed')
return chr(X)+chr(Y)
else:
print('--> Impostors')
```
In this part I explain the main "gotcha" of this solution.
The original executable code applies the following operation (that I call the 1st formula) `(a+X+Y)>>shift==b`. While trying to isolate the unknown variables `X` and `Y` on one side and the known values `shift`, `a` and `b` on the other, I got this `X+Y == (b << shift) - a` thinking it was ok when it's not.
When the shift to the right is made, information is lost. Example `0xff >> 4` is `0xf`, and doing `0xf<<4` gives `0xf0`. See? A left shift doesn't automatically "reverse the effect" of a right shift. This loss of information should be taken into account. In order to do this, we could write it this way: `0xff == 0xf<<4 + k` where `k` is a constant. We can also reasonably say that `k` in this case is at max a 4-bit value (because the right shift operation removed information from 4 bits). These two lines of my python code, found in the solution above, are a generalisation of this idea.
```python
min_sum = (b<




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}